
Building an Efficient TensorFlow Input Pipeline for Character-Level Text Generation
This tutorial is the second part of the “Text Generation in Deep Learning with Tensorflow & Keras” series.
In this tutorial series, we have been covering all the topics related to Text Generation with sample implementations in Python. In this tutorial, we will focus on how to build an Efficient TensorFlow Input Pipeline for Character-Level Text Generation.
First, we will download a sample corpus (text file). After opening the file and reading it line-by-line, we will convert it to a single line of text. Then, we will split the text into input character sequence (X) and output character (y).
Using tf.data.Dataset and Keras TextVectorization methods, we will
- preprocess the text,
- convert the characters into integer representation,
- prepare the training dataset,
- and optimize the data pipeline.
Thus, in the end, we will be ready to train a Language Model for character-level text generation.
If you would like to learn more about Deep Learning with practical coding examples, please subscribe to Murat Karakaya Akademi YouTube Channel or follow my blog on muratkarakaya.net. Do not forget to turn on notifications so that you will be notified when new parts are uploaded.

Photo by Harry Grout on Unsplash
You can access the complete code (Colab Notebook) using this link. You can read all the tf.data: Tensorflow Data Pipeline tutorials at muratkarakaya.net.
You can read all the posts about Text Generation in Deep Learning with Tensorflow & Keras Series here. You can watch all these parts on the Murat Karakaya Akademi channel on YouTube in ENGLISH or TURKISH.
Please ensure that you have reviewed the previous parts in order to utilize this part better. You can watch this tutorial on YouTube as well.
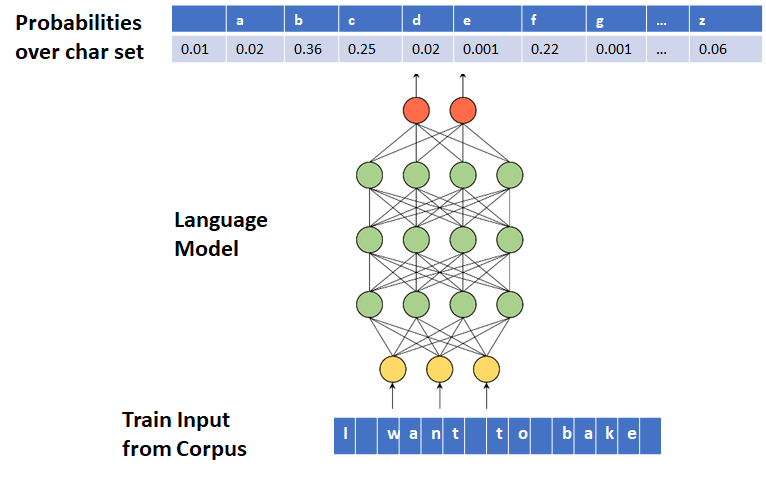
What is a Character Level Text Generation?
A Language Model can be trained to generate text character-by-character. In this case, each of the input and output tokens is a character. Moreover, Language Model outputs a conditional probability distribution over the character set.
For more details, please check Part A.
Tensorflow Data Pipeline: tf.data
What is a Data Pipeline?
Data Pipeline is an automated process that involves extracting, transforming, combining, validating, and loading data for further analysis and visualization.
It provides end-to-end velocity by eliminating errors and combatting bottlenecks or latency.
It can process multiple data streams at once.
In short, it is an absolute necessity for today’s data-driven solutions.
If you are not familiar with data pipelines, you can check my tutorials in English or Turkish. You can read all the tf.data: Tensorflow Data Pipeline tutorials at muratkarakaya.net.
Why Tensorflow Data Pipeline?
The tf.data API enables us
- to build complex input pipelines from simple, reusable pieces.
- to handle large amounts of data, read from different data formats, and perform complex transformations.
What can be done in a Text Data Pipeline?
The pipeline for a text model might involve extracting symbols from raw text data, converting them to embedding identifiers with a lookup table, and batching together sequences of different lengths.
What will we do in this Text Data pipeline?
We will create a data pipeline to prepare training data for a character-level text generator.
Thus, in the pipeline, we will
- open & load corpus (text file)
- convert the text into a sequence of characters
- remove unwanted characters such as punctuations, HTML tags, white spaces, etc.
- generate input (X) and output (y) pairs as character sequences
- concatenate input (X) and output (y) into train data
- cache, prefetch, and batch the train data for performance

After, this brief introduction to the Tensorflow Data pipeline, let’s start creating our text pipeline.
Building an Efficient TensorFlow Input Pipeline for Character-Level Text Generation
1. DOWNLOAD DATA
!curl -O https://s3.amazonaws.com/text-datasets/nietzsche.txt2. LOAD TEXT DATA LINE BY LINE
To load the data into our pipeline, I will use tf.data.TextLineDataset() method.
batch_size = 64
raw_data_ds = tf.data.TextLineDataset(["nietzsche.txt"])Let’s see some lines from the uploaded text:
for elems in raw_data_ds.take(10):
print(elems.numpy().decode("utf-8"))PREFACE
SUPPOSING that Truth is a woman--what then? Is there not ground
for suspecting that all philosophers, in so far as they have been
dogmatists, have failed to understand women--that the terrible
seriousness and clumsy importunity with which they have usually paid
their addresses to Truth, have been unskilled and unseemly methods for
winning a woman? Certainly she has never allowed herself to be won; and
at present every kind of dogma stands with sad and discouraged mien--IF,
3. COMBINE ALL LINES INTO A SINGLE TEXT
Since our aim is to prepare a training dataset for a character-level text generator, we need to convert the line-by-line text into char-by-char text.
Therefore, we first combine all line-by-line text as a single text:
text=""
for elem in raw_data_ds:
text=text+(elem.numpy().decode('utf-8'))
splitted=tf.strings.bytes_split(text)
print(text[:1000])PREFACESUPPOSING that Truth is a woman--what then? Is there not groundfor suspecting that all philosophers, in so far as they have beendogmatists, have failed to understand women--that the terribleseriousness and clumsy importunity with which they have usually paidtheir addresses to Truth, have been unskilled and unseemly methods forwinning a woman? Certainly she has never allowed herself to be won; andat present every kind of dogma stands with sad and discouraged mien--IF,indeed, it stands at all! For there are scoffers who maintain that ithas fallen, that all dogma lies on the ground--nay more, that it is atits last gasp. But to speak seriously, there are good grounds for hopingthat all dogmatizing in philosophy, whatever solemn, whatever conclusiveand decided airs it has assumed, may have been only a noble puerilismand tyronism; and probably the time is at hand when it will be onceand again understood WHAT has actually sufficed for the basis of suchimposing and absolute philosophica
4. SPLIT THE TEXT INTO TOKENS
In Part A, we mentioned that we can train a language model and generate new text by using two different units:
- character level
- word level
That is, you can split your text into a sequence of characters or words.
In this tutorial, we will focus on character-level tokenization.
If you would like to learn how to create word-level tokenization please take a look at Part C.
Check the size of the corpus
In his post, François Chollet suggested that “….make sure your corpus has at least ~100k characters. ~1M is better” to see if it suits text generation.
Let’s see the size of our corpus in chars:
print("Corpus length:", int(len(text)/1000),"K chars")Corpus length: 590 K chars
It looks like the corpus is big enough.
Check the number of distinct characters
chars = sorted(list(set(text)))
print("Total disctinct chars:", len(chars))Total disctinct chars: 83
Set the split parameters
We can split the text into two sets of fixed-size char sequences as below:
- The first sequence (
input_chars) is the input data (X) to the model which will receive a fixed-size (maxlen) character sequence - The second sequence (
next_char) is the output data (y) to the model which is only 1 char
While creating these sequences, we can jump over the data by setting step to a fixed character number.
We define all these parameters below:
# cut the text in semi-redundant sequences of maxlen characters
maxlen = 20
step = 3
input_chars = []
next_char = []Using the above parameters, we can split the text into input (X) and output (y) sequences:
for i in range(0, len(text) - maxlen, step):
input_chars.append(text[i : i + maxlen])
next_char.append(text[i + maxlen])Check the generated sequences
After splitting the text, we can check the number of sequences and see a sample input and output:
print("Number of sequences:", len(input_chars))
print("input X (input_chars) ---> output y (next_char) ")
for i in range(5):
print( input_chars[i]," ---> ", next_char[i])Number of sequences: 196980
input X (input_chars) ---> output y (next_char)
PREFACESUPPOSING tha ---> t
FACESUPPOSING that T ---> r
ESUPPOSING that Trut ---> h
PPOSING that Truth i ---> s
SING that Truth is a --->
5. CREATE X & y DATASETS
We can use these two sequences to create X and y datasets by using tf.data.Dataset.from_tensor_slices() method:
X_train_ds_raw=tf.data.Dataset.from_tensor_slices(input_chars)
y_train_ds_raw=tf.data.Dataset.from_tensor_slices(next_char)Let’s see some input-output pairs:
for elem1, elem2 in zip(X_train_ds_raw.take(5),y_train_ds_raw.take(5)):
print(elem1.numpy().decode('utf-8'),"----->", elem2.numpy().decode('utf-8'))PREFACESUPPOSING tha -----> t
FACESUPPOSING that T -----> r
ESUPPOSING that Trut -----> h
PPOSING that Truth i -----> s
SING that Truth is a ----->
6. PREPROCESS THE TEXT
We need to process these datasets before feeding them into a model.
Here, we will use the Keras preprocessing layer “TextVectorization”.
Why do we use Keras preprocessing layer?
- The Keras preprocessing layers API allows developers to build Keras-native input processing pipelines. These input processing pipelines can be used as independent preprocessing code in non-Keras workflows, combined directly with Keras models, and exported as part of a Keras SavedModel.
- With Keras preprocessing layers, we can build and export models that are truly end-to-end: models that accept raw images or raw structured data as input; models that handle feature normalization or feature value indexing on their own.
In the next part, we will create the end-to-end Text Generation model and we will see the benefits of using Keras preprocessing layers.
What are the preprocessing steps?
The processing of each sample contains the following steps:
- standardize each sample (usually lowercasing + punctuation stripping):
- In this tutorial, we will create a custom standardization function to show how to apply your code to strip unwanted chars and symbols.
- split each sample into substrings (usually words):
- As in this part, we choose to split the text into fixed-size character sequences, we will write a custom split function
- recombine substrings into tokens (usually ngrams): We will leave it as 1 ngram (char)
- index tokens (associate a unique int value with each token)
- transform each sample using this index, either into a vector of ints or a dense float vector.
Prepare custom standardization and split functions
- We have our custom standardization and split functions
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, "<br />", " ")
stripped_num = tf.strings.regex_replace(stripped_html, "[\d-]", " ")
stripped_punc =tf.strings.regex_replace(stripped_num,
"[%s]" % re.escape(string.punctuation), "")
return stripped_punc
def char_split(input_data):
return tf.strings.unicode_split(input_data, 'UTF-8')Set the text vectorization parameters
- We can limit the number of distinct characters by setting
max_features - We set an explicit
sequence_length, since our model needs fixed-size input sequences.
# Model constants.
max_features = 83 # Number of distinct chars / words
embedding_dim = 16 # Embedding layer output dimension
sequence_length = maxlen # Input sequence sizeCreate the text vectorization layer
- The text vectorization layer is initialized below.
- We are using this layer to normalize, split, and map strings to integers, so we set our ‘output_mode’ to ‘int’.
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
split=char_split, # word_split or char_split
output_mode="int",
output_sequence_length=sequence_length,
)Adapt the Text Vectorization layer to the training dataset
Now that the Text Vectorization layer has been created, we can call adapt on a text-only dataset to create the vocabulary with indexing.
You don’t have to batch, but for very large datasets this means you’re not keeping spare copies of the dataset in memory.
vectorize_layer.adapt(X_train_ds_raw.batch(batch_size))We can take a look at the size of the vocabulary
print("The size of the vocabulary (number of distinct characters): ", len(vectorize_layer.get_vocabulary()))The size of the vocabulary (number of distinct characters): 34
Let’s see the first 5 entries in the vocabulary:
print("The first 10 entries: ", vectorize_layer.get_vocabulary()[:10])The first 10 entries: ['', '[UNK]', ' ', 'e', 't', 'i', 'a', 'o', 'n', 's']
You can access the vocabulary by using an index:
vectorize_layer.get_vocabulary()[3]'e'
After preparing the Text Vectorization layer, we need a helper function to convert a given raw text to a Tensor by using this layer:
def vectorize_text(text):
text = tf.expand_dims(text, -1)
return tf.squeeze(vectorize_layer(text))A simple test of the function:
vectorize_text("Truth is a woman--what then?")<tf.Tensor: shape=(20,), dtype=int64, numpy=
array([ 4, 10, 15, 4, 11, 2, 5, 9, 2, 6, 2, 21, 7, 17, 6, 8, 2,
2, 21, 11])>
Apply the Text Vectorization onto X and y datasets
# Vectorize the data.
X_train_ds = X_train_ds_raw.map(vectorize_text)
y_train_ds = y_train_ds_raw.map(vectorize_text)
X_train_ds.element_spec, y_train_ds.element_spec(TensorSpec(shape=(20,), dtype=tf.int64, name=None),
TensorSpec(shape=(20,), dtype=tf.int64, name=None))
Convert y to a single char representation
y_train_ds=y_train_ds.map(lambda x: x[0])for elem in y_train_ds.take(1):
print("shape: ", elem.shape, "\n next_char: ",elem.numpy())shape: ()
next_char: 4
Check the tensor dimensions to ensure that we have max-sequence size inputs and a single output:
X_train_ds.take(1), y_train_ds.take(1)(<TakeDataset shapes: (20,), types: tf.int64>,
<TakeDataset shapes: (), types: tf.int64>)
Let’s see an example pair:
for (X,y) in zip(X_train_ds.take(5), y_train_ds.take(5)):
print(X.numpy()," --> ",y.numpy())[18 10 3 16 6 14 3 9 15 18 18 7 9 5 8 19 2 4 11 6] --> 4
[16 6 14 3 9 15 18 18 7 9 5 8 19 2 4 11 6 4 2 4] --> 10
[ 3 9 15 18 18 7 9 5 8 19 2 4 11 6 4 2 4 10 15 4] --> 11
[18 18 7 9 5 8 19 2 4 11 6 4 2 4 10 15 4 11 2 5] --> 9
[ 9 5 8 19 2 4 11 6 4 2 4 10 15 4 11 2 5 9 2 6] --> 2
7. FINALIZE THE DATA PIPELINE
Join the input (X) and output (y) values as a single dataset
train_ds = tf.data.Dataset.zip((X_train_ds,y_train_ds))Set data pipeline optimizations
Do async prefetching / buffering of the data for best performance on GPU
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.shuffle(buffer_size=512).batch(batch_size, drop_remainder=True).cache().prefetch(buffer_size=AUTOTUNE)Check the size of the dataset (in batches):
print("The size of the dataset (in batches)): ", train_ds.cardinality().numpy())The size of the dataset (in batches)): 3077
Again, let’s check the tensor dimensions of input X and output y:
for sample in train_ds.take(1):
print("input (X) dimension: ", sample[0].numpy().shape, "\noutput (y) dimension: ",sample[1].numpy().shape)input (X) dimension: (64, 30)
output (y) dimension: (64,)
CONCLUSION:
In this tutorial, we apply the following steps to create Tensorflow Data Pipeline for character-level text generation:
- download a corpus
- split the text into characters
- vectorize the text by using the Keras preprocessing layer “TextVectorization”
- prepare input X and output y
- optimize the data pipelines by batching, prefetching, and caching.
In the next parts, we will see
- Part C: Tensorflow Data Pipeline for Word-Level Text Generation
- Part D: Recurrent Neural Network (LSTM) Model for Character Level Text Generation
- Part E: Encoder-Decoder Model for Character Level Text Generation
- Part F: Recurrent Neural Network (LSTM) Model for Word-Level Text Generation
- Part G: Encoder-Decoder Model for Word-Level Text Generation
Comments or Questions?
Please share your Comments or Questions.
Thank you in advance.
Remember to check out the next parts!
Take care!
References
tf.data: Build TensorFlow input pipelines
Text classification from scratch
Working with Keras preprocessing layers
Character-level text generation with LSTM
Character-level text generation with LSTM
Toward Controlled Generation of Text
What is the difference between word-based and char-based text generation RNNs?
The survey: Text generation models in deep learning
Generative Adversarial Networks for Text Generation
FGGAN: Feature-Guiding Generative Adversarial Networks for Text Generation
How to sample from language models
How to generate text: using different decoding methods for language generation with Transformers
Hierarchical Neural Story Generation