
Fundamentals of Text Generation
Author: Murat Karakaya
Date created: 21 April 2021
Last modified: 19 May 2021
Description: This is an introductory tutorial on Text Generation in Deep Learning which is the first part of the “Controllable Text Generation with Transformers” series
Accessible on:

Controllable Text Generation with Transformers tutorial series
This series will focus on developing TensorFlow (TF) / Keras implementation of Controllable Text Generation from scratch.
You can access all the parts from this link or the below post.
Important
Before getting started, I assume that you have already reviewed:
- the tutorial series “Text Generation methods in Deep Learning with Tensorflow (TF) & Keras”
- the tutorial series “Sequence-to-Sequence Learning”
- the previous parts in this series
Please ensure that you have completed the above tutorial series to easily follow the below discussions.
References
Language Models:
- Yoshua Bengio, Réjean Ducharme, Pascal Vincent, Christian Janvin, A neural probabilistic language model
- A. Radford, Karthik Narasimhan, Improving Language Understanding by Generative Pre-Training (GPT)
- A. Radford, Jeffrey Wu, R. Child, David Luan, Dario Amodei, Ilya Sutskever, Language Models are Unsupervised Multitask Learners (GPT-2)
- Tom B. Brown, et.al., Language Models are Few-Shot Learners (GPT-3)
- Jay Alammar, The Illustrated GPT-2 (Visualizing Transformer Language Models)
- Murat Karakaya, Encoder-Decoder Structure in Seq2Seq Learning Tutorials: on YouTube in English or Turkish. You can also access these tutorials on Medium here.
- Sebastian Ruder, Recent Advances in Language Model Fine-tuning
- Jackson Stokes, A guide to language model sampling in AllenNLP
- Jason Brownlee, How to Implement a Beam Search Decoder for Natural Language Processing
Text Generation:
- Murat Karakaya, Text Generation with different Deep Learning Models Tutorials: on YouTube in English or Turkish. You can also access these tutorials on Medium here.
- Apoorv Nandan, Text generation with a miniature GPT
- Nicholas Renotte, Generate Blog Posts with GPT2 & Hugging Face Transformers | AI Text Generation GPT2-Large
- Mariya Yao, Novel Methods For Text Generation Using Adversarial Learning & Autoencoders
- Guo, Jiaxian and Lu, Sidi and Cai, Han and Zhang, Weinan and Yu, Yong and Wang, Jun, Long Text Generation via Adversarial Training with Leaked Information
- Patrick von Platen, How to generate text: using different decoding methods for language generation with Transformers
- Discussion Forum, What is the difference between word-based and char-based text generation RNNs?
- Papers with Code web page, Text Generation
- Ben Mann, How to sample from language models
Controllable Text Generation:
- Neil Yager, Neural text generation: How to generate text using conditional language models
- Alec Radford, Ilya Sutskever, Rafal Józefowicz, Jack Clark, Greg Brockman, Unsupervised Sentiment Neuron
- Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu, Plug and Play Language Models: A Simple Approach to Controlled Text Generation, video, code
- Ivan Lai, Conditional Text Generation by Fine-Tuning GPT-2
- Lilian Weng, Controllable Neural Text Generation
- Shrimai Prabhumoye, Alan W Black, Ruslan Salakhutdinov Exploring Controllable Text Generation Techniques, video, paper
- Muhammad Khalifa, Hady Elsahar, Marc Dymetman, A Distributional Approach to Controlled Text Generation video, paper
- Abigail See, Controlling text generation for a better chatbot
- Alvin Chan, Yew-Soon Ong, Bill Pung, Aston Zhang, Jie Fu, CoCon: A self-supervised Approach for Controlled Text Generation, video, paper
PART A1: A Review of Text Generation
What is text generation?
You train a Deep Learning (DL) model to generate random but hopefully meaningful text in the simplest form.
Text generation is a subfield of natural language processing (NLP). It leverages knowledge in computational linguistics and artificial intelligence to automatically generate natural language texts, which can satisfy certain communicative requirements.
You can visit Write With Transformer or Talk to Transformer websites to interact with several demos.
Here is a quick demo:

What is a prompt?
Prompt is the initial text input to the trained model so that it can complete the prompt by generating suitable text.
We expect that the trained model is capable of taking care of the prompt properly to generate sensible text.
In the above demo, the prompt we provided is “I believe that one day, robots will” and the trained model generates the following text:

What is a Corpus?
A corpus (plural corpora) or text corpus is a language resource consisting of a large and structured set of texts.
For example, the Large Movie Review corpus consists of 25,000 highly polar movie reviews for training, and 25,000 for testing to train a Language Model for sentiment analysis.
What is a Token?
In general, a token is a string of contiguous characters between two spaces, or between a space and punctuation marks.
A token can also be any number (an integer, or real).
All other symbols are tokens themselves except apostrophes and quotation marks in a word (with no space), which in many cases symbolize acronyms or citations.
The token can be
- a word
- a character
- a symbol
- a number
- x number of contiguous above items.
Actually, the programmer decides the size and meaning of the token in the NLP implementation.
It is the unit (granulity) of the text input to the Language Model and the output of the model as well.
Mostly, we use 3 levels for tokenization in Deep Learning applications:
- word
- character
- n-gram characters
What is Text Tokenization?
Tokenization is a way of separating a piece of text into smaller units called tokens. Basically for training a language model, we prepare the training data as follows:
First,
- we collect, clean, and structure the data
- this data is called the corpus
We decide:
- the token size (word, character, or n-gram)
- the maximum number of tokens in each sample
- the number of distinct tokens in the dictionary (vocabulary size)
Then,
- we tokenize the corpus into chunks of tokens (sequences)considering the maximum size (length) At the end of the tokenization process, we have
- sequences of tokens as samples (inputs or outputs for the LM)
- a vocabulary consisting of maximum n number of frequent tokens in the corpus
- an index list to represent each token in the dictionary
Lastly, we convert sequences of tokens to sequences of indices.
All the above steps are called tokenization and you can use Tensorflow Data Pipeline to handle these steps in a structured way. For more information about tokenization and Tensorflow Data Pipeline, see these Murat Karakaya Akademi tutorials:
- Word level tokenization Tensorflow Data Pipeline Medium blog
- Character level tokenization Tensorflow Data Pipeline Medium blog
- YouTube videos about Tensorflow Data Pipeline for tokenization in Turkish & English.
What is a Language Model?
A language model is at the core of many NLP tasks and is simply a probability distribution over a sequence of words
In this current context, the model trained to generate text is mostly called a Language Model (LM).
In a broader context, a statistical language model is a probability distribution over sequences of tokens (i.e., words or characters).
Given a prompt (assume a partial statement), say of length m, a trained Language Model (LM) assigns a conditional probability distribution over the dictionary (vocabulary) tokens $P(w_{1}$,$…$, $w_{m})$.
We can use the conditional probability distribution to select (sample) the next token to complete the given prompt.
For example, when the prompt is “I want to cook”, the trained language model can output the probability of each token in the dictionary to be the next token as below.
Then, according to the implemented sampling method, one can pick the next token considering this probability distribution.
How does a Language Model generate text?
In general, we first train an LM then make it generate text (inference).
- In training, we first prepare the train data from the corpus. Then, LM learns the conditional probability distribution of the next token for a sequence (prompt) generated from the corpus.
- In inference (text generation) mode, an LM works in a loop:
- We provide initial text (prompt) to the LM.
- The LM calculates the conditional probability of each vocabulary token to be the next token.
- We sample the next token using this conditional probability distribution.
- We concatenate this token to the seed and provide this sequence as the new seed to LM
What is Word-based and Char-based Text Generation?
We can set the token size at the word level or character level.
In the above example, the tokenization is done at the word level. Thus, the input and output of the Language Model are composed of words.
Below, you see that we opt out of character-based tokenization.
Pay attention to the above and below models’ outputs and dictionaries (vocabularies).
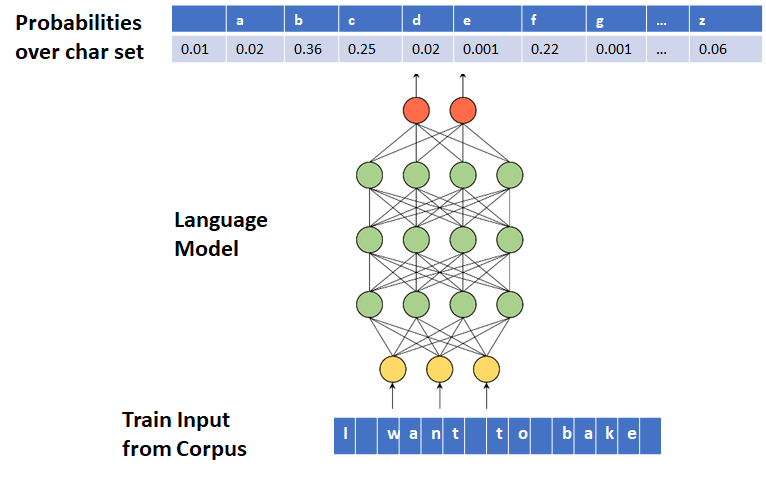
Which Level of Tokenization (Word or Character based) should be used?
In general,
- character level LMs can mimic grammatically correct sequences for a wide range of languages, require a bigger hidden layer, and computationally more expensive
- word-level LMs train faster and generate more coherent texts and yet even these generated texts are far from making actual sense.
The main advantage of character-level over word-level Text Generation models:
- Character-level models have a really small vocabulary. For example, the GBW dataset will contain approximately 800 characters compared to 800,000 words.
- In practice, this means that Character level models will require less memory and have faster inference than their word counterparts.
- Character level models do not require tokenization as a preprocessing step.
- However, Character level models require a much bigger hidden layer to successfully model long-term dependencies which mean higher computational costs.
In summary, you need to work on both to understand their advantages and disadvantages.
What is Sampling?
Sampling means randomly picking the next word according to its conditional probability distribution. After generating a probability distribution over vocabulary for the given input sequence, we need to carefully decide how to select the next token (sample) from this distribution.
There are several methods for sampling in text generation such as:
- Greedy Search (Maximization)
- Temperature Sampling
- Top-K Sampling
- Top-P Sampling (Nucleus sampling)
- Beam Search
You can learn details of these sampling methods and how to code them with Tensorflow / Keras in these Murat Karakaya Akademi tutorials:
Also, you can visit the blog by Patrick von Platen, How to generate text: using different decoding methods for language generation with Transformers.
What kinds of Language Models do exist in Artificial Neural Networks?
The most popular approaches to create a Language Model in Deep Learning are:
- Recurrent Neural Networks (LSTM or GRU)
- Encoder-Decoder Models
- Transformers
- Generative Adversarial Networks (GANs)
Which Language Model to use?
The LMs mentioned above have their advantages and disadvantages.
In a very short and simple comparison:
- Transformers are novel models but they require much more data to be trained with.
- RNNs can not create coherent long sequences
- Encoder-Decoder models enhanced with Attention Mechanism could perform better than RNNs but worse than Transformers
- GANs can not be easily trained or converge.
As a researcher or developer, we need to know how to apply all these three approaches on text generation problem.
Text Generation Types
Mainly, we can think of 2 types of text generation approach:
- Random Text Generation: The LM is free to generate any text without being limited or directed by any specific rules or expectations. We only hope for realistic, coherent, understandable content to be generated.
- Controllable Text Generation: Controllable text generation generates natural sentences whose attributes can be controlled. For example, we can define some attributes of the text to be generated such as:
- tense
- sentiment
- structure
- grammar
- consist of some key terms/topics
For example, in this work, the authors train an LM such that it can control the tense (present or past) and attitude (positive or negative) of the generated text like below:
Text Generation Summary
So far, we have reviewed the important concepts and methods related to Text Generation in Deep Learning.
If you want to go deeper and see how to implement several Language Models (LSTM, Encoder-Decoder, etc.) with Python / TensorFlow / Keras you can refer to the following Text Generation with different Deep Learning Models resources provided by Murat Karakaya Akademi :)
- on YouTube in English or Turkish
- on Blogger
Furthermore, you might need to check the above references for more details.
If you want to learn Controllable Text Generation Fundamentals and how to implement it with different Deep Learning models in Python, TensorFlow & Keras please continue with the next parts.
You can access all the parts from this link.
Comments or Questions?
Please share your Comments or Questions.
Thank you in advance.
Do not forget to check out the next parts!
Take care!