
Character Level Text Generation with an LSTM Model
This tutorial is the fifth part of the “Text Generation in Deep Learning with Tensorflow & Keras” series. In this series, we have been covering all the topics related to Text Generation with sample implementations in Python, Tensorflow & Keras.
In this tutorial, we will focus on how to build a Language Model using Keras LSTM layer for Character Level Text Generation. First, we will download a sample corpus (text file). After opening the file, we will apply the TensorFlow input pipeline that we have developed in Part B to prepare the training dataset by preprocessing and splitting the text into input character sequence (X) and output character (y). Then, we will design an LSTM-based Language Model and trai n it using the train set. Later on, we will apply several sampling methods that we have implemented in Part D to generate text and observe the effect of these sampling methods on the generated text. Thus, in the end, we will have a trained LSTM-based Language Model for character-level text generation with three sampling methods.
You can access all the parts of the Text Generation in Deep Learning with Tensorflow & Keras tutorial series on my blog at muratkarakaya.net. You can watch all these parts on the Murat Karakaya Akademi channel on YouTube in ENGLISH or TURKISH. You can access this Colab Notebook using the link.
If you would like to learn more about Deep Learning with practical coding examples, please subscribe to Murat Karakaya Akademi YouTube Channel or follow my blog at muratkarakaya.net. Do not forget to turn on notifications so that you will be notified when new parts are uploaded.
If you are ready, let’s get started!

Photo by Jan Huber on Unsplash
I assume that you have already watched all the previous parts.
Please ensure that you have reviewed the previous parts to utilize this part better.
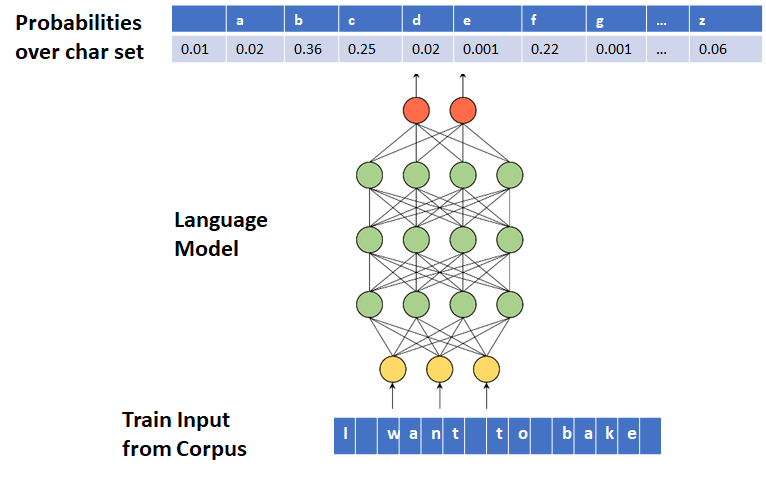
What is a Character Level Text Generation?
A Language Model can be trained to generate text character-by-character. In this case, each of the input and output tokens is a character. Moreover, Language Model outputs a conditional probability distribution over the character set.
For more details, please check Part A.
1. BUILD A TENSORFLOW INPUT PIPELINE
What is a Data Pipeline?
Data Pipeline is an automated process that involves extracting, transforming, combining, validating, and loading data for further analysis and visualization.
It provides end-to-end velocity by eliminating errors and combatting bottlenecks or latency.
It can process multiple data streams at once.
In short, it is an absolute necessity for today’s data-driven solutions.
If you are not familiar with TF data pipelines, you can check my tutorials in English or Turkish or at my blog muratkarakaya.net.
What will we do in this Text Data pipeline?
We will create a data pipeline to prepare training data for a character-level text generator.
Thus, in the pipeline, we will
- open & load corpus (text file)
- convert the text into a sequence of characters
- remove unwanted characters such as punctuations, HTML tags, white spaces, etc.
- generate input (X) and output (y) pairs as character sequences
- concatenate input (X) and output (y) into train data
- cache, prefetch, and batch the train data for performance
For more information please refer to Part B: Tensorflow Data Pipeline for Character Level Text Generation on Youtube ( ENGLISH / TURKISH) or my blog at muratkarakaya.net.
Input for the TensorFlow Pipeline
# For English text
!curl -O https://s3.amazonaws.com/text-datasets/nietzsche.txt% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 586k 100 586k 0 0 702k 0 --:--:-- --:--:-- --:--:-- 701k# For Turkish text
#!curl -O https://raw.githubusercontent.com/kmkarakaya/ML_tutorials/master/data/mesnevi_Tumu.txt
TensorFlow Pipeline
For more information and the complete code please refer to Part B: Tensorflow Data Pipeline for Character Level Text Generation on Youtube ( ENGLISH / TURKISH) or my blog at muratkarakaya.net.
Result of the Data Pipeline:
for sample in train_ds.take(1):
print("input (X) dimension: ", sample[0].numpy().shape, "\noutput (y) dimension: ",sample[1].numpy().shape)input (X) dimension: (64, 20)
output (y) dimension: (64,)for sample in train_ds.take(1):
print("input (sequence of chars): ", sample[0][0].numpy(), "\noutput (next char to complete the input): ",sample[1][0].numpy())input (sequence of chars): [ 8 4 6 5 8 2 4 11 6 4 2 5 4 11 6 9 2 16 6 12] output (next char to complete the input): 12for sample in train_ds.take(1):
print("input (sequence of chars): ", decode_sequence (sample[0][0].numpy()), "\noutput (next char to complete the input): ",vectorize_layer.get_vocabulary()[sample[1][0].numpy()])input (sequence of chars): al timesuch as the
output (next char to complete the input): s
2. PREPARE SAMPLING METHODS
In Text Generation, sampling means randomly picking the next token according to the generated conditional probability distribution.
That is, after generating the conditional probability distribution over the set of tokens (vocabulary) for the given input sequence, we need to carefully decide how to select the next token (sample) from this distribution.
There are several methods for sampling in text generation (see here and here):
- Greedy Search (Maximization)
- Temperature Sampling
- Top-K Sampling
- Top-P Sampling (Nucleus sampling)
- Beam Search
In this tutorial, we will code Greedy Search, Temperature Sampling, and Top-K Sampling.
For more information about Sampling, please review Part D: Sampling in Text Generation on Youtube ( ENGLISH / TURKISH) or my blog at muratkarakaya.net.
def softmax(z):
return np.exp(z)/sum(np.exp(z))def greedy_search(conditional_probability):
return (np.argmax(conditional_probability))def temperature_sampling (conditional_probability, temperature=1.0):
conditional_probability = np.asarray(conditional_probability).astype("float64")
conditional_probability = np.log(conditional_probability) / temperature
reweighted_conditional_probability = softmax(conditional_probability)
probas = np.random.multinomial(1, reweighted_conditional_probability, 1)
return np.argmax(probas)def top_k_sampling(conditional_probability, k):
top_k_probabilities, top_k_indices= tf.math.top_k(conditional_probability, k=k, sorted=True)
top_k_probabilities= np.asarray(top_k_probabilities).astype("float32")
top_k_probabilities= np.squeeze(top_k_probabilities)
top_k_indices = np.asarray(top_k_indices).astype("int32")
top_k_redistributed_probability=softmax(top_k_probabilities)
top_k_redistributed_probability = np.asarray(top_k_redistributed_probability).astype("float32")
sampled_token = np.random.choice(np.squeeze(top_k_indices), p=top_k_redistributed_probability)
return sampled_token
3 A LSTM-BASED LANGUAGE MODEL FOR TEXT GENERATION
In this tutorial, we will use the Keras LSTM layer to create a Language Model for character-level text generation.
3.1 Define the model
As we already prepared the training dataset, we need to define the input specs accordingly.
Remember that in the train set, the length of the input (X) sequence (sequence_length) is 20 tokens (chars). Thus, we provide this info to the embedding layer.
Next, we add a layer to map those vocab indices into a space of dimensionality ‘embedding_dim’.
After applying Dropout, we use an LSTM layer to process the sequence and learn to generate the next token with the help of a Dense layer.
Here is the complete code:
inputs = tf.keras.Input(shape=(sequence_length), dtype="int64")
x = layers.Embedding(max_features, embedding_dim)(inputs)
x = layers.Dropout(0.5)(x)
x = layers.LSTM(128, return_sequences=True)(x)
x = layers.Flatten()(x)
predictions= layers.Dense(max_features, activation='softmax')(x)
model_LSTM = tf.keras.Model(inputs, predictions,name="model_LSTM")3.2 Compile the model
Since we use integers to represent the output (Y), that is; we do not use one-hot encoding, we need to use sparse_categorical_crossentropy loss function.
model_LSTM.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model_LSTM.summary())Model: "model_LSTM"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 20)] 0
_________________________________________________________________
embedding (Embedding) (None, 20, 16) 1536
_________________________________________________________________
dropout (Dropout) (None, 20, 16) 0
_________________________________________________________________
lstm (LSTM) (None, 20, 128) 74240
_________________________________________________________________
flatten (Flatten) (None, 2560) 0
_________________________________________________________________
dense (Dense) (None, 96) 245856
=================================================================
Total params: 321,632
Trainable params: 321,632
Non-trainable params: 0
_________________________________________________________________
None
3.3 Train the model
We train the Language Model for 3 epochs.
model_LSTM.fit(train_ds, epochs=3)Epoch 1/3
3077/3077 [==============================] - 30s 10ms/step - loss: 1.8037 - accuracy: 0.4592
Epoch 2/3
3077/3077 [==============================] - 30s 10ms/step - loss: 1.7858 - accuracy: 0.4636
Epoch 3/3
3077/3077 [==============================] - 30s 10ms/step - loss: 1.7677 - accuracy: 0.4680
<tensorflow.python.keras.callbacks.History at 0x7f7f4b8f6710>
3.4 An Auxillary Function for Decoding Token Index to Characters
We need to convert the given token index to the corresponding character for each token in the generated text. Therefore, I prepare the decode_sequence () function as below:
def decode_sequence (encoded_sequence):
deceoded_sequence=[]
for token in encoded_sequence:
deceoded_sequence.append(vectorize_layer.get_vocabulary()[token])
sequence= ''.join(deceoded_sequence)
print("\t",sequence)
return sequence3.5 Another Auxillary Function for Generating Text
To generate text with various sampling methods, I prepare the following function. The generate_text(model, prompt, step) function takes the trained Language Model, the prompt, and the length of the text to be generated as the parameters. Then, it generates text with three different sampling methods.
def generate_text(model, seed_original, step):
seed= vectorize_text(seed_original)
print("The prompt is")
decode_sequence(seed.numpy().squeeze())
seed= vectorize_text(seed_original).numpy().reshape(1,-1)
#Text Generated by Greedy Search Sampling
generated_greedy_search = (seed)
for i in range(step):
predictions=model.predict(seed)
next_index= greedy_search(predictions.squeeze())
generated_greedy_search = np.append(generated_greedy_search, next_index)
seed= generated_greedy_search[-sequence_length:].reshape(1,sequence_length)
print("Text Generated by Greedy Search Sampling:")
decode_sequence(generated_greedy_search)
#Text Generated by Temperature Sampling
print("Text Generated by Temperature Sampling:")
for temperature in [0.2, 0.5, 1.0, 1.2]:
print("\ttemperature: ", temperature)
seed= vectorize_text(seed_original).numpy().reshape(1,-1)
generated_temperature = (seed)
for i in range(step):
predictions=model.predict(seed)
next_index = temperature_sampling(predictions.squeeze(), temperature)
generated_temperature = np.append(generated_temperature, next_index)
seed= generated_temperature[-sequence_length:].reshape(1,sequence_length)
decode_sequence(generated_temperature)
#Text Generated by Top-K Sampling
print("Text Generated by Top-K Sampling:")
for k in [2, 3, 4, 5]:
print("\tTop-k: ", k)
seed= vectorize_text(seed_original).numpy().reshape(1,-1)
generated_top_k = (seed)
for i in range(step):
predictions=model.predict(seed)
next_index = top_k_sampling(predictions.squeeze(), k)
generated_top_k = np.append(generated_top_k, next_index)
seed= generated_top_k[-sequence_length:].reshape(1,sequence_length)
decode_sequence(generated_top_k)We can call the generate_text() function by providing the trained LM, a prompt and the sequence length of the text to be generated as below.
You can run this method multiple times to observe the generated text with different sampling methods.
generate_text(model_LSTM,"WHO is it really that puts questions to", 100)The output is:
The prompt is
who is it really tha
Text Generated by Greedy Search Sampling:
who is it really that the soul of the same to the berieve the sense of the soul of the sempeth of the soul of the sempet
Text Generated by Temperature Sampling:
temperature: 0.2
who is it really that the soul of the some the same of the soul of the same that the more and the soul of the sempates a
temperature: 0.5
who is it really that the secfit semelt of the soul and the sor to as a wire it is which as as its rame to the beadts
temperature: 1.0
who is it really that wath tokest oud were abere at saed af any though niff to bolevse of the names bes rose it by rvab
temperature: 1.2
who is it really that positions of jenw cisns oruaritions anither which thenringurcomsome itality his our gagacin astoo
Text Generated by Top-K Sampling:
Top-k: 2
who is it really than his dot to be and secf assemethe intentious as a cropessious of all thing one sindtence of his oth
Top-k: 3
who is it really thasthisc here ass isthaction which heare of als actiable havifin be at a sinntlys hiss hor tath
Top-k: 4
who is it really that werendivanse astains or silcussine attainss into thoug howy athort the himselv an ascimicustselved
Top-k: 5
who is it really thattisserftut isturctyd for tomliatif sace of croselyd soungher ar indepfimiessinfstialtitude it o
4 OBSERVATIONS
Info about the corpus
- The size of the vocabulary (number of distinct characters): 34
- The number of generated sequences: 196980
- The maximum length of sequences: 20
Note that this corpus actually is not sufficient to generate high-quality texts. However, due to the limitations of the Colab platform (RAM and GPU), I used this corpus for demonstration purposes.
Therefore, please keep in mind these limitations when considering the generated texts.
About the Language Modle
- We implement a single-LSTM-layer model. Thus, we do not expect this simple model to create high-quality texts.
- On the other hand, you can try to improve this model by incrementing the number of LSTM layers, the output dimension of the embedding and LSTM layers, etc.
Greedy Search
- The method simply selects the token with the highest probability as its next token (word or char).
- However, if we always sample the most likely word, the standard language model training objective causes us to get stuck in loops like above.
Temperature Sampling
- If the temperature is set to very low values or 0, then Temperature Sampling becomes equivalent to the Greedy Search and results in extremely repetitive and predictable text.
- With higher temperatures, the generated text becomes more random, interesting, surprising, even creative; it may sometimes invent completely new words (misspelled words) that sound somewhat plausible.
Top-k Sampling
- In the studies, it is reported that the top-k sampling appears to improve quality by removing the tail and making it less likely to go off-topic.
- However, in our case, there are not many tokens we could sample from reasonably (broad distribution).
- Thus, in the above examples, Top-K generates texts that mostly look random.
- Therefore, the k value should be chosen carefully concerning the size of the token dictionary.
CONCLUSION:
In this tutorial, we apply the following steps to generate character-level text generation:
- download a corpus
- apply the Tensorflow Data Pipeline
- create a Language Model based on the Keras LSTM layer
- use three sampling methods
In the next parts, we will see
- Part E: Encoder-Decoder Model for Character Level Text Generation
- Part F: Recurrent Neural Network (LSTM) Model for Word Level Text Generation
- Part G: Encoder-Decoder Model for Word Level Text Generation
Comments or Questions?
Please share your Comments or Questions.
Thank you in advance.
Do not forget to check out the next parts!
Take care!
References
tf.data: Build TensorFlow input pipelines
Text classification from scratch
Working with Keras preprocessing layers
Character-level text generation with LSTM
Toward Controlled Generation of Text
What is the difference between word-based and char-based text generation RNNs?
The survey: Text generation models in deep learning
Generative Adversarial Networks for Text Generation
FGGAN: Feature-Guiding Generative Adversarial Networks for Text Generation
How to sample from language models
How to generate text: using different decoding methods for language generation with Transformers
Hierarchical Neural Story Generation
How to sample from language models
A guide to language model sampling in AllenNLP
Generating text from the language model
How to Implement a Beam Search Decoder for Natural Language Processing
Controllable Neural Text Generation