
Seq2Seq Learning Part A: Introduction & A Sample Solution with MLP Network
If you are interested in Seq2Seq Learning, I have good news for you. Recently, I have been working on Seq2Seq Learning and I decided to prepare a series of tutorials about Seq2Seq Learning from a simple Multi-Layer Perceptron Neural Network model to an Encoder-Decoder Model with Attention.
You can access all my SEQ2SEQ Learning videos on Murat Karakaya Akademi Youtube channel in ENGLISH or in TURKISH
You can access all the tutorials in this series from my blog on www.muratkarakaya.net
Thank you!

Photo by Hal Gatewood on Unsplash
Fundamentals of Sequence to sequence (Seq2Seq) learning
Definitions:
- Sequence: A particular order in which related things follow each other.
- Seq2Seq learning: Sequence-to-sequence learning (Seq2Seq) is about training models to convert sequences from one domain (e.g. sentences in English) to sequences in another domain (e.g. the same sentences translated to French)
- Parallel Data Sets: Like most machine-learning models, effective Seq2Seq Learning requires massive amounts of training data in order to produce correct results. A parallel data set is a structured set of sequences between input and output. Such parallel data sets are essential for training Seq2Seq models.


Examples of sequence to sequence problems:
- Machine Translation — An artificial system that translates a sentence from one language to the other.
- Video Captioning — Automatically creating the subtitles of a video for each frame
- Image Captioning — Automatically creating the descriptions of an image
- Text Summarization — Condensing a piece of text to a shorter version, reducing the size of the initial text while at the same time preserving key informational elements and the meaning of the content
- Question Answering — Generating a natural language answer given a natural language question
- Conversational Modeling — Simulating a conversation (or a chat) with a user in natural language through messaging applications, websites, mobile apps, or the telephone.
- Speech Recognition — Converting a speech to text
- Time series forecasting — Predicting future values based on previously observed values of a time series. Most commonly, a time series is a sequence taken at successive equally spaced points in time: heights of ocean tides, counts of sunspots, and the daily closing value of the Dow Jones Industrial Average.
How to categorize Seq2Seq Learning Problems
According to the length of input & output sequences:
- these lengths can be fixed or variable
According to the data types of input & output sequences:
- these can be the same (text: from one language to another language)
- these can be different or mixed (image in text out: Image Captioning)
In real life, most problems have variable lengths and mixed data types of input & output sequences. We begin with a fixed-length and same data type sequence problem. In the upcoming parts, we will develop the model such that it will be able to handle variable-length sequence problems as well.
How to solve Seq2Seq Learning Problems
There are several approaches to solving Seq2Seq Problems. In this series, we will focus on Encoder-Decoder Model/Paradigm. Encoder-Decoder Model/Paradigm is based on neural networks that map the input of a sequence to an output of a sequence with a tag and attention value.
In the implementation, Recurrent Neural Networks or Convolutional Neural Networks can be used.
The main advantage of the Encoder-Decoder framework is that it requires little feature engineering and domain specificity.
In this series, we will go over several models:
- Multi-Layer Perceptron (MLP) network
- Recurrent Neural Network
- Base Encoder-Decoder model with LSTM
- Encoder-Decoder model with Teacher Forcing
- Encoder-Decoder model with Bahdanau (Additive) Attention Mechanism
- Encoder-Decoder model with Loung (Dot-product) Attention Mechanism
- Encoder-Decoder model with Beam Search
Need to know:
- Keras/TF
- Recurrent network concepts
- LSTM parameters and outputs
- Keras Functional API
A Simple Seq2Seq Learning Problem:
Assume that:
- We are given a parallel data set including X (input) and y (output) such that X[i] and y[i] have some relationship
- For instance: we are given the same book’s text in English (X) and in Turkish (y)
- Thus the statement X[i] in English is translated into Turkish as y[i] statement
- We use the parallel date set to train a seq2seq model which would learn how to convert/transform an input sequence from X to an output sequence (y)
I will generate X and y parallel datasets such that y sequence will be the reverse of the given X sequence
- Given sequence X[i] length of 4:
X[i]=[3, 2, 9, 1]
- Output sequence (y[i]) is the reversed input sequence (X[i])
y[i]=[1, 9, 2, 3]
In real life (like Machine Language Translation, Image Captioning, etc.), we are given (or build) a parallel dataset: X sequences and corresponding y sequences
- To set up an easily traceable example, I opt out to set y sequences as the reversed of X sequences
- However, you can create X and y parallel datasets as you wish: sorted, reverse sorted, odd or even numbers selected, etc.
IMPORTANT:
In this sample sequence problem, input (X) and output (y) sequences have fixed and the same length and same data type. In upcoming tutorials, after we built a basic encoder-decoder model, we will change/relax the problem such that we will be dealing with variable-length sequences and different data types.
WHY WE HAVE SO MANY PARTS?
Our aim is to code an Encoder-Decoder with Attention. However, I would like to develop the solution by showing the shortcomings of other possible approaches. Therefore, in the first 2 parts, we will observe that initial models have their own weaknesses. We also understand why the Encoder-Decoder paradigm is so successful.
So, please patiently follow the parts as we develop a better solution :)
PART A: Using Multi-Layer Perceptron network
We will develop an MLP model for fixed-size and same-data type input and output sequences
Configure the Sample Parallel Data Set
- Number of Input Timesteps: how many tokens / distinct events /numbers/word etc in the input sequence
- Number of Features: how many features/dimensions are used to represent one token /distinct events/numbers/word etc
- Here, we use one-hot encoding to represent the integers.
- The length of the one-hot coding vector is the Number of Features
- Thus, the greatest integer will be the Number of Features-1
- When Number of Features=10 the greatest integer will be 9 and will be represents as [0 0 0 0 0 0 0 0 0 1]
Note:
For the full code please check Colab Notebook.
You can watch this video on Youtube Murat Karakaya Akademi channel
#@title Configure problem
n_timesteps_in = 4
#each input sample has 4 values
n_features = 10
#each value is one_hot_encoded with 10 0/1
#n_timesteps_out = 2
#each output sample has 2 values padded with 0
# generate random sequence
X,y = get_reversed_pairs(n_timesteps_in, n_features, verbose=True)
# generate datasets
train_size= 20000
test_size = 200
X_train, y_train , X_test, y_test=create_dataset(train_size, test_size, n_timesteps_in,n_features , verbose=True)Sample X and y
In raw format:
X[0]=[3, 5, 5, 5], y[0]=[5, 5, 5, 3]
In one_hot_encoded format:
X[0]=[[0 0 0 1 0 0 0 0 0 0]
[0 0 0 0 0 1 0 0 0 0]
[0 0 0 0 0 1 0 0 0 0]
[0 0 0 0 0 1 0 0 0 0]]
y[0]=[[0 0 0 0 0 1 0 0 0 0]
[0 0 0 0 0 1 0 0 0 0]
[0 0 0 0 0 1 0 0 0 0]
[0 0 0 1 0 0 0 0 0 0]]
Generated sequence datasets as follows
X_train.shape: (20000, 4, 10) y_train.shape: (20000, 4, 10)
X_test.shape: (200, 4, 10) y_test.shape: (200, 4, 10)
time: 568 ms
An MLP MODEL
Create
We will begin with creating a simple Multi-Layer Perceptron network
#@title Multi-Layer Perceptron network
numberOfPerceptrons=64
model_Multi_Layer_Perceptron = Sequential(name='model_Multi_Layer_Perceptron')
model_Multi_Layer_Perceptron.add(Input(shape=(n_timesteps_in, n_features)))
model_Multi_Layer_Perceptron.add(Dense(4*numberOfPerceptrons))
model_Multi_Layer_Perceptron.add(Dense(2*numberOfPerceptrons))
model_Multi_Layer_Perceptron.add(Dense(numberOfPerceptrons))
model_Multi_Layer_Perceptron.add(Dense(n_features, activation='softmax'))
model_Multi_Layer_Perceptron.compile(loss='categorical_crossentropy', optimizer='adam',
metrics=['accuracy'])
model_Multi_Layer_Perceptron.summary()
plot_model(model_Multi_Layer_Perceptron,show_shapes=True)Model: "model_Multi_Layer_Perceptron"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 4, 256) 2816
_________________________________________________________________
dense_1 (Dense) (None, 4, 128) 32896
_________________________________________________________________
dense_2 (Dense) (None, 4, 64) 8256
_________________________________________________________________
dense_3 (Dense) (None, 4, 10) 650
=================================================================
Total params: 44,618
Trainable params: 44,618
Non-trainable params: 0
_________________________________________________________________

time: 545 msTrain & Test
We will train & test the simple Multi-Layer Perceptron model:
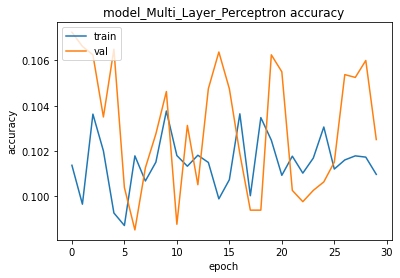
train_test(model_Multi_Layer_Perceptron, X_train, y_train , X_test, y_test, verbose=2)training for 500 epochs begins with EarlyStopping(monitor= val_loss, patience=20)....
Epoch 1/500
563/563 - 2s - loss: 2.3085 - accuracy: 0.1014 - val_loss: 2.3038 - val_accuracy: 0.1072
......
563/563 - 2s - loss: 2.3027 - accuracy: 0.1017 - val_loss: 2.3020 - val_accuracy: 0.1060
Epoch 30/500
563/563 - 2s - loss: 2.3026 - accuracy: 0.1010 - val_loss: 2.3022 - val_accuracy: 0.1025
Epoch 00030: early stopping
500 epoch training finished...
PREDICTION ACCURACY (%):
Train: 10.352, Test: 9.750

some examples...
Input [1, 3, 6, 6] Expected: [6, 6, 3, 1] Predicted [0, 7, 5, 5] False
Input [9, 3, 0, 9] Expected: [9, 0, 3, 9] Predicted [7, 7, 7, 7] False
Input [1, 5, 8, 9] Expected: [9, 8, 5, 1] Predicted [0, 0, 7, 7] False
Input [6, 2, 4, 7] Expected: [7, 4, 2, 6] Predicted [5, 0, 7, 0] False
Input [8, 4, 4, 3] Expected: [3, 4, 4, 8] Predicted [7, 7, 7, 7] False
Input [8, 8, 3, 0] Expected: [0, 3, 8, 8] Predicted [7, 7, 7, 7] False
Input [1, 2, 0, 6] Expected: [6, 0, 2, 1] Predicted [0, 0, 7, 5] False
Observations & Conclusions:
- We learned the Seq2Seq Learning Problem
- We designed and configured a sample Seq2Seq Learning problem which we will be using during the tutorials
- We coded a simple Multi-Layer Perceptron (MLP) model by Keras Sequential API
- We learn and run the train_test function
- We observed that MLP did not perform well (about 10% accuracy) WHY?
- Using Recurrent Neural Networks could be a good idea. WHY?
Write your argument in the comments below, please. I will provide feedback on your comments.
Thank you for reading
KMK
SEQ2SEQ LEARNING SERIES:
You can access all SEQ2SEQ Learning videos on Murat Karakaya Akademi Youtube channel in ENGLISH or in TURKISH
You can access all the parts on my blog on muratkarakaya.net
References:
Blogs:
- tf.keras.layers.LSTM official website
- A ten-minute introduction to sequence-to-sequence learning in Keras by Francois Chollet
- How to Develop an Encoder-Decoder Model with Attention in Keras by Jason Brownlee
Presentations:
Videos:
Notebooks:
- LSTM intro by Murat Karakaya Akademi
- Understanding LSTM output types and dimensions by Murat Karakaya Akademi
- How to calculate Keras LSTM layer parameter numbers by Murat Karakaya Akademi