
SEQ2SEQ LEARNING PART D: Encoder-Decoder with Teacher Forcing
Welcome to Part D of the Seq2Seq Learning Tutorial Series. In this tutorial, we will design an Encoder-Decoder model to be trained with “Teacher Forcing” to solve the sample Seq2Seq problem introduced in Part A.
We will use the LSTM layer in Keras as the Recurrent Neural Network.
You can access all my SEQ2SEQ Learning videos on Murat Karakaya Akademi Youtube channel in ENGLISH or in TURKISH
You can access all the tutorials in this series from my blog at www.muratkarakaya.net. If you would like to follow up on Deep Learning tutorials, please subscribe to my YouTube Channel or follow my blog on muratkarakaya.net. You can also access this Colab Notebook using the link.
If you are ready, let’s get started!

Photo by Vedrana Filipović on Unsplash
REMINDER:
- This is Part D of the Seq2Seq Learning series.
- Please check out the previous part to refresh the necessary background knowledge in order to follow this part with ease.
A Simple Seq2Seq Problem: The reversed sequence problem
Assume that:
- We are given a parallel data set including X (input) and y (output) such that X[i] and y[i] have some relationship
In that tutorial, I will generate X and y parallel datasets such that the y sequence will be the reverse of the given X sequence. For example,
- Given sequence X[i] length of 4:
X[i]=[3, 2, 9, 1]
- Output sequence (y[i]) is the reversed input sequence (X[i])
y[i]=[1, 9, 2, 3]
I will call this parallel dataset: “the reversed sequence problem”
In real life (like Machine Language Translation, Image Captioning, etc.), we are given (or build) a parallel dataset: X sequences and corresponding y sequences
- However, to set up an easily traceable example, I opt out to set y sequences as the reversed of X sequences
- However, you can create X and y parallel datasets as you wish: sorted, reverse sorted, odd, or even numbers selected, etc.
- We use the parallel data set to train a seq2seq model which would learn
- how to convert/transform an input sequence from X to an output sequence in y
IMPORTANT:
- In the reversed sequence problem, the input & output sequence lengths are fixed and the same.
- In PART E, we will change the problem and the solution such that we will be dealing with variable-length sequences after we built the encoder-decoder model.
Configure the problem
- Number of Input Timesteps: how many tokens / distinct events /numbers / word etc in the input sequence
- Number of Features: how many features/dimensions are used to represent one tokens / distict events / numbers / word etc
- Here, we use one-hot encoding to represent the integers.
- The length of the one-hot coding vector is the Number of Features
- Thus, the greatest integer will be the Number of Features-1
- When the Number of Features=10 the greatest integer will be 9 and will be represented as [0 0 0 0 0 0 0 0 0 1]
#@title Configure problem
n_timesteps_in = 4#@param {type:"integer"}
#each input sample has 4 values
n_features = 10 #@param {type:"integer"}
#each value is one_hot_encoded with 10 0/1
#n_timesteps_out = 2 #@param {type:"integer"}
#each output sample has 2 values padded with 0
# generate random sequence
X,y = get_reversed_pairs(n_timesteps_in, n_features, verbose=True)
# generate datasets
train_size= 2000 #@param {type:"integer"}
test_size = 200 #@param {type:"integer"}
X_train, y_train , X_test, y_test=create_dataset(train_size, test_size, n_timesteps_in,n_features , verbose=True)Sample X and y
In raw format:
X=[7, 3, 6, 5], y=[5, 6, 3, 7]
In one_hot_encoded format:
X=[[0 0 0 0 0 0 0 1 0 0]
[0 0 0 1 0 0 0 0 0 0]
[0 0 0 0 0 0 1 0 0 0]
[0 0 0 0 0 1 0 0 0 0]]
y=[[0 0 0 0 0 1 0 0 0 0]
[0 0 0 0 0 0 1 0 0 0]
[0 0 0 1 0 0 0 0 0 0]
[0 0 0 0 0 0 0 1 0 0]]
Generated sequence datasets as follows
X_train.shape: (2000, 4, 10) y_train.shape: (2000, 4, 10)
X_test.shape: (200, 4, 10) y_test.shape: (200, 4, 10)
time: 77.6 ms
Before starting, you need to know:
- Python
- Keras/TF
- Deep Neural Networks
- Recurrent Neural Network concepts
- LSTM parameters and outputs
- Keras Functional API
- Basics of Encoder-Decoder approach
If you would like to refresh your knowledge about the above topics please check Murat Karakaya Akademi resources on YouTube / Medium / COLAB
A Quick Reminder: Encoder & Decoder
- The encoder encodes the input into a new representation
- The decoder decodes the encoded representation of the input into the output
Note: There are other proposed methods to solve seq2seq problems such as Conv models or Reinforcement methods. In this tutorial, we focus on Enoder- Decoder architecture.

Key Concepts
- Training: During training, we train the encoder and decoder such that they work together to create a context (representation) between input and output
- Inference (Prediction): After learning how to create the context (representation), they can work together to predict the output
- Encode all- decode one at a time: Mostly, the encoder reads all the input sequences and creates a context (representation) vector. Decoder use this context (representation) vector and previously decoded results to create new output step by step.
- Teacher forcing: During training decoder receives the correct output from the training set as the previously decoded result to predict the next output. However, during inference decoder receives the previously decoded result to predict the next output. Teacher forcing improves the training process.
DO NOT WORRY! WE WILL SEE ALL THE ABOVE CONCEPTS IN ACTION BELOW!
LSTMoutputDimension = 16 HOW TO TRAIN A GENERIC ENCODER—DECODER
- The decoder produces the output sequence one by one
- For each output, the decoder consumes a context vector and an input
- The initial context vector is created by the encoder
- The initial input is a special symbol for the decoder to make it start, e.g. ‘start’
- Using initial context and initial input, the decoder will generate the first output
- For the next output, the decoder will use its current state as a context vector and generated (predicted) output as input
- The decoder will work in such a loop using its state and output as the next step context vector and input until the generated output is a special symbol ‘stop’ or the pre-defined maximum steps (length of output) are reached.

HOW TO USE A GENERIC ENCODER—DECODER FOR INFERENCE (PREDICTION)
- We provide an input sequence (X_test) to the trained encoder-decoder model
- The trained encoder-decoder model outputs the predicted sequence
HOW TO TRAIN AN ENCODER-DECODER WITH TEACHER FORCING
The initial steps are the same:
- The decoder produces the output sequence one by one
- For each output, the decoder consumes a context vector and an input
- The initial context vector is created by the encoder
- The initial input is a special symbol for the decoder to make it start, e.g. ‘start’
- Using initial context and initial input, the decoder will generate the first output

However, the input to the decoder during the loop is different
- For the next output,
- the decoder will use its current state as a context vector and generated (predicted) output as input
- we (the teacher!) provide the correct output to the decoder as input
- The difference is: the decoder uses the context vector and the correct input to the next output rather than using its prediction in the previous cycle
- The decoder will work in such a loop using its state and output provided correct output as the next step context vector and input until the generated output is a special symbol ‘stop’ or the pre-defined maximum steps (length of output) is reached.
Therefore, we need to provide 2 input sequences to train AN ENCODER — DECODER WITH TEACHER FORCING such that
- input to encoder: [4 7 2 8]
- input to decoder: [0 8 2 7]
Note that:
- The expected output is [8 2 7 4] — — reverse of input to the encoder
- 0 (zero) is selected as a special symbol for ‘start’
- input to the decoder is created by shifting the expected output by one-time step and adding a ‘start’ token as the first token:
- [8 2 7 4] — — → [0 8 2 7]
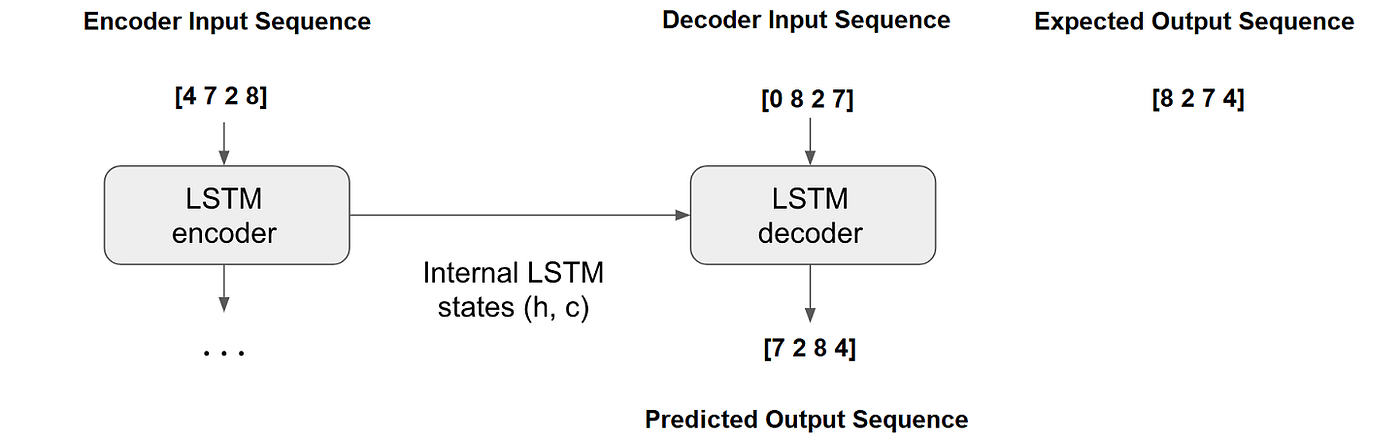
During training:
- In the first cycle, the decoder will use the encoder’s state and its first input which is 0 from the decoder input sequence [0 8 2 7] to generate the first output which is expected to be 8 from [8 2 7 4]
- Assume that the decoder predicts 7
- In the generic Encoder-Decoder model, the decoder will use 7 to generate/predict the next token
- In teacher forcing, we (the teacher!) provide the second input from [0 8 2 7] which is 8 to the decoder to generate/predict the next token
Thus, during training, the teacher enforces the decoder to condition itself to generate/predict the next token according to the given correct input!
HOW TO USE AN ENCODER—DECODER MODEL TRAINED WITH TEACHER FORCING FOR INFERENCE (PREDICTION)
- We need 2 input sequences:
- Input for encoder: encoder_inputs
- Input for decoder: decoder_inputs
- The encoder_inputs is given
- However, this time we do not have the correct outputs
- Therefore, we will provide the predicted output as the input.
- The first input is ‘start’ and the other inputs will be the outputs from the previous cycle
CREATE AN ENCODER—DECODER MODEL WITH TEACHER FORCING TO TRAIN
- Define the model that will turn
encoder_input_data&decoder_input_dataintodecoder_predicted_data - complete the decoder model by adding a Dense layer with Softmax activation function for prediction of the next output
- The dense layer will output one-hot encoded representation as we did for the input
- Therefore, we will use n_features number of neurons
# TRAINING WITH TEACHER FORCING
# Define an input sequence and process it.
encoder_inputs= Input(shape=(n_timesteps_in, n_features))
encoder_lstm=LSTM(LSTMoutputDimension, return_state=True)
LSTM_outputs, state_h, state_c = encoder_lstm(encoder_inputs)
# We discard `LSTM_outputs` and only keep the other states.
encoder_states = [state_h, state_c]
decoder_inputs = Input(shape=(None, n_features), name='decoder_inputs')
decoder_lstm = LSTM(LSTMoutputDimension, return_sequences=True, return_state=True, name='decoder_lstm')
# Set up the decoder, using `context vector` as initial state.
decoder_outputs, _, _ = decoder_lstm(decoder_inputs,
initial_state=encoder_states)
#complete the decoder model by adding a Dense layer with Softmax activation function
#for prediction of the next output
#Dense layer will output one-hot encoded representation as we did for input
#Therefore, we will use n_features number of neurons
decoder_dense = Dense(n_features, activation='softmax', name='decoder_dense')
decoder_outputs = decoder_dense(decoder_outputs)
# put together
model_encoder_training = Model([encoder_inputs, decoder_inputs], decoder_outputs, name='model_encoder_training')time: 489 ms
- compile the model
model_encoder_training.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
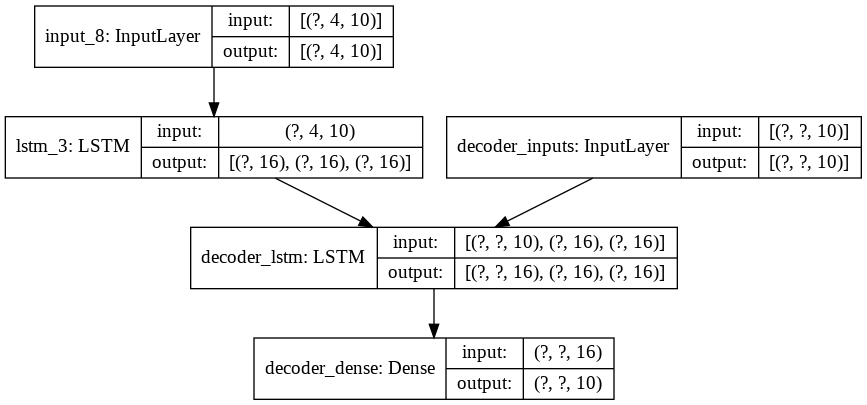
model_encoder_training.summary()
plot_model(model_encoder_training, show_shapes=True)Model: "model_encoder_training"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_8 (InputLayer) [(None, 4, 10)] 0
__________________________________________________________________________________________________
decoder_inputs (InputLayer) [(None, None, 10)] 0
__________________________________________________________________________________________________
lstm_3 (LSTM) [(None, 16), (None, 1728 input_8[0][0]
__________________________________________________________________________________________________
decoder_lstm (LSTM) [(None, None, 16), ( 1728 decoder_inputs[0][0]
lstm_3[0][1]
lstm_3[0][2]
__________________________________________________________________________________________________
decoder_dense (Dense) (None, None, 10) 170 decoder_lstm[0][0]
==================================================================================================
Total params: 3,626
Trainable params: 3,626
Non-trainable params: 0
__________________________________________________________________________________________________
time: 103 msPREPARE TRAINING DATASETS
- To train the Encoder-Decoder model we need to work on the train data set such that we will prepare 3 data sets:
- Input for encoder (encoder_inputs): all sequences of 1 sample training input data (X)
- Input for the decoder (decoder_inputs): 1 token from 1 sample training target sequence (y) for teacher forcing [should start with ‘start’ symbol]
- The target for the decoder (decoder_predicted_data): 1 token from 1 sample training target sequence (y) [should end with ‘end’ symbol]
- We can modify the code such that the first number (0) of the input domain numbers is reserved for ‘start’ and ‘end’ symbols as follows:
Generated sequence datasets as follows
X_encoder_in.shape: (5000, 4, 10)
X_decoder_in.shape: (5000, 4, 10)
y_decoder_out.shape: (5000, 4, 10)
Sample sequences in raw format:
X_encoder_in:
[8, 8, 9, 3]
X_decoder_in:
[0, 3, 9, 8]
y_decoder_out:
[3, 9, 8, 8]
Sample sequences in one-hot encoded format:
X_encoder_in:
[[0 0 0 0 0 0 0 0 1 0]
[0 0 0 0 0 0 0 0 1 0]
[0 0 0 0 0 0 0 0 0 1]
[0 0 0 1 0 0 0 0 0 0]]
X_decoder_in:
[[1 0 0 0 0 0 0 0 0 0]
[0 0 0 1 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 1]
[0 0 0 0 0 0 0 0 1 0]]
y_decoder_out:
[[0 0 0 1 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 1]
[0 0 0 0 0 0 0 0 1 0]
[0 0 0 0 0 0 0 0 1 0]]
time: 232 ms- We train the model while monitoring the loss on a held-out set of 20% of the samples as below.
- However, I prepared a custom
train_testfunction for getting a detailed report of training and testing.
# Run training
model_encoder_training.fit([encoder_input_data, decoder_input_data], decoder_predicted_data,
batch_size=32,
epochs=50,
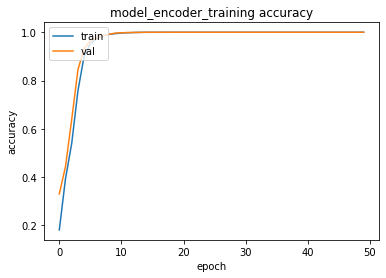
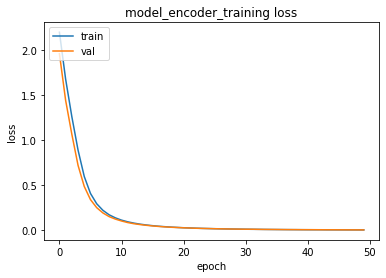
validation_split=0.2)train_test(model_encoder_training, [encoder_input_data, decoder_input_data], decoder_predicted_data , [encoder_input_data, decoder_input_data], decoder_predicted_data, epochs=50, batch_size=32, patience=5,verbose=2)training for 50 epochs begins with EarlyStopping(monitor= val_loss, patience= 5 )....
Epoch 1/50
141/141 - 1s - loss: 2.1932 - accuracy: 0.1816 - val_loss: 1.9553 - val_accuracy: 0.3305
...
Epoch 49/50
141/141 - 1s - loss: 0.0023 - accuracy: 1.0000 - val_loss: 0.0026 - val_accuracy: 1.0000
Epoch 50/50
141/141 - 1s - loss: 0.0022 - accuracy: 1.0000 - val_loss: 0.0024 - val_accuracy: 1.0000
50 epoch training finished...
PREDICTION ACCURACY (%):
Train: 100.000, Test: 100.000
10 examples from test data...
Input Expected Predicted T/F
[8, 8, 9, 3] [3, 9, 8, 8] [3, 9, 8, 8] True
[1, 7, 5, 9] [9, 5, 7, 1] [9, 5, 7, 1] True
[3, 5, 6, 5] [5, 6, 5, 3] [5, 6, 5, 3] True
[2, 3, 3, 9] [9, 3, 3, 2] [9, 3, 3, 2] True
[5, 4, 3, 5] [5, 3, 4, 5] [5, 3, 4, 5] True
[4, 2, 1, 5] [5, 1, 2, 4] [5, 1, 2, 4] True
[9, 5, 2, 4] [4, 2, 5, 9] [4, 2, 5, 9] True
[9, 8, 5, 5] [5, 5, 8, 9] [5, 5, 8, 9] True
[2, 9, 9, 7] [7, 9, 9, 2] [7, 9, 9, 2] True
[7, 2, 9, 8] [8, 9, 2, 7] [8, 9, 2, 7] True
Accuracy: 1.0
time: 37.2 s- We observed that training is finalized with almost 100% accuracy with validation training sets
IMPORTANT: Please note that we execute validation and testing by just using the training data and Teacher Forcing in place!!!
- WHY?
Because:
- Teacher Forcing needs to know the correct output beforehand
- Teacher Forcing is a method for improving the training process
- The model employing Teacher Forcing CAN NOT BE USED in inference/testing
Therefore,
- the model that we trained above CAN NOT BE DIRECTLY USED in inference/testing
- We will use some layers (with their weights) of the trained model to create a new model
- The new model will not use Teacher Learning
- Thus, the input to the new model will NOT BE
[encoder_input_data, decoder_input_data]as the way we designed inmodel_encoder_training - Remember, in Teacher Forcing, we set
decoder_input_datasuch that it begins with a special symbolstartand continues with the target sequence data except for the last time step. - Now, during inference (testing), we do not know the correct (expected) target data beforehand!
- We define the
decoder_input_dataas follows: - it begins with a special symbol
start - it will continue with an input created by the decoder at the previous time step
- in other words, the decoder’s output at time step t will be used decoder’s input at time step t+1
Let’s begin to design an encoder-decoder model for inference
We create a separate encoder model by using the trained layers in the above model
IMPORTANT: pay attention that in this model we use encoder_inputs, encoder_states for encoding which are parts of the encoder model, we trained above. That is, these layers come with its **trained weights **with Teacher Forcing
encoder_model = Model(encoder_inputs, encoder_states)time: 11 ms
Then we create a separate decoder model by using the trained layers in the above model
- Design the decoder model by defining layers for:
- inputs
- decoding (LSTM)
- outputs
IMPORTANT: pay attention that in this model we use decoder_lstm for decoding which is a part of the decoder model, we trained above. That is this layer comes with its trained weights with Teacher Forcing
decoder_state_input_h = Input(shape=(LSTMoutputDimension,))
decoder_state_input_c = Input(shape=(LSTMoutputDimension,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(
decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model(
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs] + decoder_states)time: 237 ms
- Even though we define the encoder and decoder models we still need to dynamically provide the
decoder_input_dataas follows: - it begins with a special symbol
start - it will continue with an input created by the decoder at the previous time step
- in other words, the decoder’s output at time step t will be used decoder’s input at time step t+1
- Let’s code it as a function:
def decode_sequence(input_seq):
# Encode the input as state vectors.
states_value = encoder_model.predict(input_seq)
# Generate empty target sequence of length 1.
target_seq = np.zeros((1, 1, n_features))
# Populate the first character of target sequence with the start character.
target_seq[0, 0, 0] = 1
# Sampling loop for a batch of sequences
# (to simplify, here we assume a batch of size 1).
stop_condition = False
decoded_seq = list()
while not stop_condition:
# in a loop
# decode the input to a token/output prediction + required states for context vector
output_tokens, h, c = decoder_model.predict(
[target_seq] + states_value)
# convert the token/output prediction to a token/output
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_digit = sampled_token_index
# add the predicted token/output to output sequence
decoded_seq.append(sampled_digit)
# Exit condition: either hit max length
# or find stop character.
if (sampled_digit == '\n' or
len(decoded_seq) == n_timesteps_in):
stop_condition = True
# Update the input target sequence (of length 1)
# with the predicted token/output
target_seq = np.zeros((1, 1, n_features))
target_seq[0, 0, sampled_token_index] = 1.
# Update input states (context vector)
# with the ouputed states
states_value = [h, c]
# loop back.....
# when loop exists return the output sequence
return decoded_seqtime: 22.4 ms
We can now put the encoder model and decoder model together by using the function above for inference as below.
IMPORTANT:
- Since we used the trained layers here we do NOT need to train recently created models.
- We only provide the input sequence to the function.
print('Input \t\t\t Expected \t Predicted \t\tT/F')
correct =0
sampleNo = 10
for sample in range(0,sampleNo):
predicted= decode_sequence(encoder_input_data[sample].reshape(1,n_timesteps_in,n_features))
if (one_hot_decode(decoder_predicted_data[sample])== predicted):
correct+=1
print( one_hot_decode(encoder_input_data[sample]), '\t\t',
one_hot_decode(decoder_predicted_data[sample]),'\t', predicted,
'\t\t',one_hot_decode(decoder_predicted_data[sample])== predicted)
print('Accuracy: ', correct/sampleNo)Input Expected Predicted T/F
[8, 8, 9, 3] [3, 9, 8, 8] [3, 9, 8, 8] True
[1, 7, 5, 9] [9, 5, 7, 1] [9, 5, 7, 1] True
[3, 5, 6, 5] [5, 6, 5, 3] [5, 6, 5, 3] True
[2, 3, 3, 9] [9, 3, 3, 2] [9, 3, 3, 2] True
[5, 4, 3, 5] [5, 3, 4, 5] [5, 3, 4, 5] True
[4, 2, 1, 5] [5, 1, 2, 4] [5, 1, 2, 4] True
[9, 5, 2, 4] [4, 2, 5, 9] [4, 2, 5, 9] True
[9, 8, 5, 5] [5, 5, 8, 9] [5, 5, 8, 9] True
[2, 9, 9, 7] [7, 9, 9, 2] [7, 9, 9, 2] True
[7, 2, 9, 8] [8, 9, 2, 7] [8, 9, 2, 7] True
Accuracy: 1.0
time: 1.96 s
Observations:
- Teacher Forcing is a method to train encoder-decoder models in the Seq2Seq model to accelerate training
- Teacher Forcing can ONLY be used at Training
- We need to handle how to use the model in inference
- Even though Teacher Forcing improves the training process by fast converging, in the inference the model can generate low accuracy even with the training data.
- Therefore, you need to use Teacher Forcing with caution
What if I don’t want to use teacher forcing for training?
- Please look at the previous part on how to implement an Encoder-Decoder without Teacher Forcing training:
References:
References:
You can follow me on these social networks: