
Sayılarla Büyük Dil Modellerinin İmkan ve Kabiliyetleri: LLM'lerin Mimarisi, Yetenekleri ve Muhakeme Gücü
Merhaba sevgili Murat Karakaya Akademi takipçileri!
Bugün sizlerle son birkaç yılın en dönüştürücü teknolojisi olan Büyük Dil Modelleri (BDM veya İngilizce kısaltmasıyla LLM) üzerine derinlemesine bir yolculuğa çıkacağız. Bu teknoloji, ChatGPT'nin iki ay gibi inanılmaz bir sürede 100 milyon aktif kullanıcıya ulaşmasıyla
Bu yazıda, elinizdeki sunumun tüm detaylarını kullanarak bu soruların yanıtlarını arayacağız.
Eğer bu konuyu bir de video üzerinden dinlemek isterseniz, sunumun detaylı anlatımını yaptığım YouTube videomuza da göz atmanızı şiddetle tavsiye ederim.
Hazırsanız, Büyük Dil Modellerinin büyüleyici dünyasına dalalım!
Büyük Dil Modelleri Neden Bu Kadar Önemli? Sayılarla Panoramik Bir Bakış
Bir teknolojinin önemini anlamanın en iyi yollarından biri, yarattığı etkiyi somut verilerle görmektir. BDM'ler söz konusu olduğunda, rakamlar gerçekten de baş döndürücü. Gelin bu "yapay zeka patlamasının" ardındaki çarpıcı kanıtlara birlikte göz atalım.
Tablo 1 ve Tablo 2 olarak referans vereceğimiz veriler, dört ana eksende durumu özetliyor:


İnanılmaz Yayılım Hızı: Reuters'ın bildirdiğine göre ChatGPT, aylık 100 milyon aktif kullanıcıya sadece iki ayda ulaşarak internet tarihindeki "en hızlı büyüyen uygulama" unvanını kazandı
. Bu, daha önce Instagram, TikTok gibi fenomenlerin bile yıllarını alan bir başarıydı. Bu durum, BDM tabanlı uygulamaların ne kadar sezgisel ve kitleler tarafından ne kadar hızlı benimsenebilir olduğunu gösteriyor. -
Kurumsal Dünyada Derin Entegrasyon: Bu teknoloji sadece son kullanıcılar arasında popüler olmakla kalmadı. McKinsey & Company tarafından 2025 için yapılan küresel bir anket, şimdiden şirketlerin %75'inden fazlasının en az bir iş fonksiyonunda Üretken Yapay Zeka (Generative AI) kullandığını ortaya koyuyor
. Pazarlama metinleri oluşturmaktan yazılım kodlamaya, müşteri hizmetlerinden finansal analizlere kadar sayısız alanda BDM'ler aktif olarak değer üretiyor. -
Devasa Pazar Büyüklüğü ve Sermaye Akışı: Rakamlar, bu alanın ekonomik potansiyelini de gözler önüne seriyor. Grand View Research'e göre, Üretken Yapay Zeka pazarının 2024'te 17.109 milyar dolarlık bir değere ulaşması ve 2030'a kadar yıllık yaklaşık %30'luk bileşik büyüme oranıyla (YBBO) büyümesi bekleniyor
. Bu potansiyelin farkında olan yatırımcılar da boş durmuyor. CB Insights verilerine göre, 2024 yılında risk sermayesi (VC) fonlarının %37'si gibi dikkat çekici bir oranı doğrudan yapay zeka girişimlerine aktarıldı . Bu, inovasyonun ve yeni BDM tabanlı çözümlerin artarak devam edeceğinin en net göstergesi. -
Bilimsel Üretkenlikte Çığır Açan Etki: BDM'lerin en heyecan verici etkilerinden biri de bilim dünyasında yaşanıyor. arXiv'de yayınlanan ve 67.9 milyon makaleyi analiz eden bir çalışma, yapay zeka araçlarını kullanan araştırmacıların %67 daha fazla yayın yaptığını ve tam 3.16 kat daha fazla atıf aldığını bulguladı
. Bu, BDM'lerin sadece mevcut bilgiyi özetlemekle kalmayıp, hipotez geliştirmeden veri analizine kadar bilimsel keşif sürecini hızlandıran bir katalizör olduğunu kanıtlıyor.
Özetle: Karşımızdaki tablo, BDM'lerin geçici bir heves olmadığını; aksine, internetin icadı veya mobil devrim gibi temel bir teknolojik dönüşüm olduğunu net bir şekilde ortaya koyuyor.
LLM'lerin Mimarisi, Yetenekleri ve Muhakeme Gücü: Nasıl Bu Kadar Akıllandılar?
Peki, bu modellerin bu kadar etkileyici yeteneklere ulaşmasının ardında ne yatıyor? Cevap, son yıllarda mimarilerinde yaşanan devrimsel sıçramalarda gizli.
Mimari Sıçramalar ve Temel Kavramlar
Eskiden dil modelleri daha basit ve kural tabanlıyken, 2017'de tanıtılan Transformer Mimarisi her şeyi değiştirdi. Ancak asıl "akıllanma" süreci, bu temel mimari üzerine inşa edilen yenilikçi katmanlarla gerçekleşti.

Tablo 3'e baktığımızda, günümüzün en güçlü modellerinin (GPT-4.1, Llama 4 Scout, Gemini 1.5 Pro, GPT-4o) ortak bazı mimari özelliklere sahip olduğunu görüyoruz
-
Spars Mixture-of-Experts (MoE): Bu, belki de en önemli mimari yenilik. Geleneksel bir model, bir görevi çözmek için devasa ve tek parça bir sinir ağı kullanır. MoE ise bu yaklaşımı değiştirir. Modeli, her biri belirli konularda uzmanlaşmış daha küçük "uzman" (expert) ağlara böler. Bir "yönlendirici" (router) katmanı, gelen veriyi analiz eder ve görevi en iyi çözeceğine inandığı uzman veya uzmanlara yönlendirir.
- Nasıl Uygulanır? Bu mimari, modelleri hem eğitirken hem de çalıştırırken çok daha verimli hale getirir. Tüm devasa ağı çalıştırmak yerine sadece ilgili uzmanları aktive ederek hesaplama maliyetini düşürür. Örneğin, GPT-4.1'in yaklaşık 16 uzmana sahip olduğu belirtiliyor
. Bu, modelin hem daha hızlı hem de daha yetenekli olmasını sağlar. Sunumumuzdaki Şekil 5, standart bir Transformer bloğu ile MoE bloğu arasındaki farkı görsel olarak harika bir şekilde anlatmaktadır. Şekillerde, MoE mimarisindeki "Router" katmanının gelen görevi nasıl farklı uzmanlara dağıttığını görebilirsiniz.


-
Çoklu Mod (Multimodality): İlk dil modelleri sadece metin anlıyor ve üretiyordu. Tablo 3'teki modern modeller ise metin, görsel, ses ve hatta video gibi birden çok veri türünü aynı anda işleyebiliyor
. Örneğin, Gemini 1.5 Pro'nun video dahil çoklu mod desteği sunması, ona bir film fragmanı izletip özetini istemenizi veya bir grafik tasarımın kodunu yazdırmanızı mümkün kılıyor . -
Devasa Bağlam Penceresi (Context Window): Bağlam penceresi, bir modelin tek seferde ne kadar bilgiyi hafızasında tutabildiğini belirtir. İlk modeller birkaç sayfalık metni zor hatırlarken, Meta'nın Llama 4 Scout modelinin 10 milyon token'lık bağlam penceresi, neredeyse bir kütüphaneyi aynı anda analiz edebilmesi anlamına gelir
. Bu, modelin çok uzun belgelerdeki veya karmaşık kod tabanlarındaki bağlantıları kurabilmesi, tutarlılığı koruyabilmesi ve derinlemesine muhakeme yapabilmesi için kritik bir yetenektir.
Muhakemenin Sınırları: En Yeni "Reasoning" Modelleri ve Ortak Başarı Formülleri
BDM'ler sadece bilgi depolamakla kalmıyor, aynı zamanda karmaşık problemler üzerinde "akıl yürütebiliyor". Tablo 4, bu alandaki en yeni modeller olan OpenAI o3 ve DeepSeek R1 gibi sistemlerin kullandığı ortak teknikleri listeliyor

Bu modellerin başarısının ardındaki ortak paydalar şunlardır
-
MoE + Retrieval (Getirme): Yukarıda bahsettiğimiz MoE mimarisi, genellikle Retrieval-Augmented Generation (RAG) olarak bilinen bir teknikle birleştirilir. RAG, modelin bir soruya cevap vermeden önce kendi iç bilgisinin dışına çıkıp güncel ve güvenilir veritabanlarından veya belgelerden ilgili bilgiyi "getirmesini" (retrieve) sağlar. Böylece model, hem daha doğru ve güncel cevaplar verir hem de "halüsinasyon" olarak bilinen bilgi uydurma eğilimini azaltır.
-
Zincirleme Düşünce (Chain-of-Thought - CoT) ve Plan-and-Execute: Bu, modelin bir soruyu yanıtlarken düşünme sürecini adım adım açıklamasıdır. Model, karmaşık bir problemi daha küçük, yönetilebilir adımlara böler. "Plan-and-Execute" ise bu tekniği bir adım ileri taşır: Model önce bir çözüm planı oluşturur, sonra bu planı adım adım uygular ve her adımda kendini kontrol eder. Bu, özellikle matematik ve kodlama gibi çok adımlı mantık gerektiren görevlerde başarıyı artırır
. -
Emniyet Katmanı (Guard-Rail): Bu güçlü modellerin sorumlu bir şekilde kullanılması hayati önem taşır. "Guard-Rail" olarak adlandırılan emniyet katmanları, modelin zararlı, etik dışı veya tehlikeli içerikler üretmesini engellemek için tasarlanmış filtreler ve kontrol mekanizmalarıdır
.
Pratik İpucu: Kendi projelerinizde bir BDM kullanacaksanız, sadece modelin gücüne değil, bu gelişmiş muhakeme ve güvenlik tekniklerini destekleyip desteklemediğine de bakın. Özellikle kurumsal bir çözüm geliştiriyorsanız, RAG ve Guard-Rail yetenekleri olmazsa olmazdır.
Sayılarla Büyük Dil Modellerinin Gücü: Başarım Testleri ve IQ Metaforu
Modellerin mimarisini anladık, peki performanslarını nasıl objektif olarak ölçebiliriz? Bu noktada devreye benchmark yani başarım testleri giriyor.
MMLU Benchmark'ı Nedir?
Sunumumuzun 13. sayfası, sektördeki en saygın testlerden biri olan MMLU (Massive Multitask Language Understanding) hakkında bize detaylı bilgi veriyor
- Tanım: 2021'de OpenAI tarafından tanıtılan MMLU, dil modellerinin genel bilgi ve akıl yürütme becerilerini ölçen kapsamlı bir testtir
. - Kapsam: STEM (bilim, teknoloji, mühendislik, matematik), sosyal bilimler, beşeri bilimler ve hukuk gibi profesyonel konular dahil olmak üzere toplam 57 farklı alanı kapsar
. Sorular, ortaokul seviyesinden lisansüstü uzmanlık seviyesine kadar geniş bir yelpazede yer alır . - Amaç: Modelin sadece ezberlenmiş bilgiyi değil, farklı disiplinlerdeki bilgisini kullanarak muhakeme yapma ve problem çözme yeteneğini test etmektir
. - İnsn Performansı: Bu testte, alanında uzman bir insanın ortalama başarımının yaklaşık %89 olduğu kabul edilir
. Bu, modellerin performansını karşılaştırmak için bize önemli bir referans noktası sunar.
Muhakeme Gücünün Karşılaştırması
Şekil 6 Artificial Analysis Intelligence Index grafiği, güncel modellerin bu zorlu testlerdeki performansını gözler önüne seriyor. Grafikte, GPQA Diamond ve AIME gibi insanüstü düzeyde zor kabul edilen yarışma sorularını içeren testlerde, OpenAI'nin o3 ve xAI'nin Grok 3 gibi modellerinin skorlarının, uzman-insan bandının üst sınırına dayandığını veya geçtiğini görüyoruz
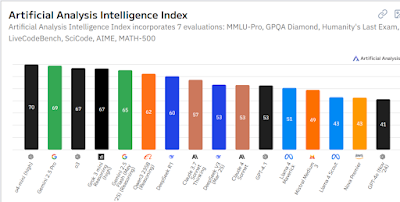
Bir IQ Metaforu: Yapay Zeka Ne Kadar "Zeki"?
Modellerin bu başarım skorlarını daha anlaşılır kılmak için ilginç bir metafor kullanılıyor: IQ testi.
Lifearchitect web sitesinde sunulan analiz, bu konuda çarpıcı bir perspektif sunuyor. Bu analize göre, ortalama bir insanın MMLU'daki %34'lük performansı kabaca 100 IQ puanına denk kabul ediliyor
- GPT-4.1 → IQ ≈ 260
- Gemini 2.5 Pro → IQ ≈ 248
- Grok 3 β → IQ ≈ 235
Önemli Not: Elbette bu bir metafordur. BDM'ler insanlar gibi bilinçli veya duygusal bir zekaya sahip değildir. Bu "IQ" skoru, sadece belirli bilişsel görevlerdeki problem çözme yeteneklerini, insanlarla kıyaslanabilir bir ölçeğe oturtma denemesidir. Yine de bu karşılaştırma, modellerin ulaştığı yetkinlik seviyesini anlamak için güçlü bir araçtır. Sunumun 16. sayfasındaki Şekil 7'de yer alan ve farklı modelleri bir IQ dağılım eğrisi üzerinde gösteren grafik, bu durumu görsel olarak özetlemektedir.

Sonuç, Öneriler ve Geleceğe Bakış
Bu derinlemesine yolculuğun sonuna gelirken, vardığımız sonuçlar oldukça net. Sunumun kapanış sayfasında da vurgulandığı gibi: "LLM’ler iş değeri yaratmada çarpıcı bir kaldıraç sağlıyor; ancak eşzamanlı risk eğrisi de hızla tırmanıyor."
Bu, bir yanda verimlilikte, inovasyonda ve bilimsel keşifte eşi benzeri görülmemiş fırsatlar sunan, diğer yanda ise yanlış bilgi, güvenlik açıkları ve etik sorunlar gibi ciddi riskler barındıran çift taraflı bir kılıçtır.
Peki ne yapmalıyız?
- Yöneticiler ve Liderler İçin: BDM'leri bir "sihirli değnek" olarak görmekten ziyade, stratejik bir araç olarak ele alın. Kurumunuzdaki en büyük verimsizliklerin veya en değerli fırsatların nerede olduğunu belirleyin ve BDM'leri bu noktalara odaklanarak küçük, kontrol edilebilir pilot projelerle test edin.
- Geliştiriciler ve Mühendisler İçin: Sadece API kullanmanın ötesine geçin. MoE, RAG, CoT gibi temel mimarileri ve teknikleri anlamaya çalışın. Bu, size sadece daha iyi uygulamalar geliştirme değil, aynı zamanda modellerin sınırlarını ve potansiyel zayıflıklarını anlama yeteneği de kazandıracaktır. Güvenlik (Guard-Rails) ve sorumlu yapay zeka prensiplerini projelerinizin en başına koyun.
- Tüm Teknoloji Meraklıları İçin: Bu alandaki gelişmeleri takip etmeye devam edin. Öğrenin, deneyin ve sorgulayın. Bu teknoloji, önümüzdeki on yılda hayatımızın her alanını şekillendirecek ve bu dönüşümün bir parçası olmak, hem kişisel hem de profesyonel gelişiminiz için kritik öneme sahip olacak.
Bu heyecan verici ve bir o kadar da karmaşık konu hakkındaki düşüncelerinizi merak ediyorum. Siz ne düşünüyorsunuz?
Bu detaylı analizi faydalı bulduysanız ve yapay zeka, veri bilimi gibi konularda daha fazla derinlemesine içerik görmek istiyorsanız, Murat Karakaya Akademi YouTube kanalına abone olmayı unutmayın! Desteğiniz, daha fazla kaliteli içerik üretmemiz için bize ilham veriyor.